-
[논문공부] Denoising Diffusion Probabilistic Models (DDPM) 설명Deep-learning 2021. 7. 9. 21:51
─ 들어가며 ─
심심할때마다 아카이브에서 머신러닝 카테고리에서 그날 올라온 논문들이랑 paperswithcode를 봅니다. 아카이브 추세나 ICLR, ICML 등 주변 지인들 학회 쓰는거 보니까 이번 상반기에는 diffusion model을 많이 변형해서 쓰고 있었습니다.
이전까지는 그런게 있나보다 하고 그냥 새로운 generative model중 하나겠거니 하고 잠깐의 유행이겠거니 하고 넘겼는데 paperswithcode에 어느날 이런게 하나 올라옵니다.
https://paperswithcode.com/paper/diffusion-models-beat-gans-on-image-synthesis
Papers with Code - Diffusion Models Beat GANs on Image Synthesis
🏆 SOTA for Image Generation on ImageNet 64x64 (FID metric)
paperswithcode.com
아주 어그로가 안끌릴수가 없는 제목으로 한동안 최상단에 차지하고 있었어서 나름 열심히 공부를 해보게 되었습니다.
code는 후속 포스트에서 공부해보고, 일단은 어떤 논문인지 본 포스트에서 설명하겠습니다.
─ VAE설명만큼의 수학이 등장합니다 ─
0. 간단히

"noising process의 역과정을 수학적으로 나타내서 역과정을 학습하는 방법이 DDPM" Diffusion process에서는 원래 이미지가 있을때 이것에 아주 조금(nearly infinitesimal) 노이즈화시키고, 이것을 다회 반복(논문 실험에서는 1000회)하여 원래 이미지와 거의 independent한 noise로 만듭니다.
Neural network는 이 nearly infinitesimal한 diffusion process의 역과정인 reverse process의 coefficient를 학습하게 됩니다.
1. 논문 용어/수식 설명
1-1) Diffusion process(from data to noise)
"What distinguishes diffusion models from other types of latent variable models is that the approximate posterior $q(x_{1:t}|x_0)$, called the forward process or diffusion process, is fixed to a Markov chain that gradually adds Gaussian noise to the data according to a variance schedule $\beta_1, \beta_2, ..., \beta_t$:

The forward process variances $\beta_t$ can be learned by reparameterization or held constant as hyperparameters" - DDPM paper에서 발췌
논문내에서 $q$는 diffusion process이며 미세한 Gaussian noise를 추가하는 과정(정확히는 noise화 되는 과정)입니다.
VAE에서 사용하는 reparameterization trick으로 학습할 수 있으나, 이 논문에서는 hyperparameter로 사용하였습니다. 즉 diffusion process에는 trainable parameter가 없습니다.
추가로 $q$는 점점 걷어내지는 과정 상에서 Markov chain입니다. 즉, 만일 $x_{t-1}$이 condition으로 주어진다면 $x_{t-1}$ 이전의 $x_{t-2}, x_{t-3}, ...$에 independent합니다. 또한 $x$의 아래 첨자는 0에서 T까지의 process 과정을 표현하는데, $x_0$는 noise가 없는 데이터이고, $t$가 커짐에 따라 점점 noisy해져서 $x_T$는 Gaussian noise가 됩니다.
1-2) Reverse process(from noise to data)
"Diffusion models are latent variable models of the form $p_\theta(x_0):=\frac{1}{2\pi}$ \(\int_{-\infty}^{\infty} p_\theta(x_{0:T}) \,dx_{1:T}\) , where $x_1, x_2, ..., x_T$ are latents of the same dimensionality as the data $x_0~q(x_0)$. The joint distribution $p_\theta(x_{0:T})$ is called the reverse process, and it is defined as a Markov chain with learned Gaussian transitions starting at $p(x_T) = N(x_T;0,I)$" - DDPM paper에서 발췌

논문내에서 $p$는 reverse process이며 미세한 Gaussian noise를 걷어내는 과정입니다. 아래 첨자로 $\theta$를 포함하도록 하여 neural network로 학습되는 확률 모델임을 명시하였습니다. diffusion process와 마찬가지로 $p$ 또한 Markov chain입니다.
─ 중간 정리 ─
DDPM 논문의 핵심은 neural network로 표현되는 $p$ 모델이 $q$를 보고 noise를 걷어내는 과정을 학습하는 것입니다. 그런데 1-1)에서 설명했듯, $q$는 noise를 아주 조금 추가하는 process입니다(정확하게는 아주 조금 noisy해지는 process). 단순히 $q$의 $\mu$ (mean), $\sigma$ (std)와 같아지도록 학습한다면 $p$ 또한 당연히 noise가 추가되는 process로 학습될 것입니다.
$q$ process를 보고 어떻게 $p$가 denoising process가 되게 학습시킬 수 있을까요?

2. DDPM loss - 수식의 홍수
(여기서는 논문의 설명을 위한 여러 수식이 나타납니다. 학습 방법과 논문 결과를 보고싶으시면 3, 4로 skip하세요.)
2-1) Variational Autoencoder(VAE)
VAE loss 수식을 유도하는 과정을 복습해보면 다음과 같습니다. 자세한 설명은 다른 블로그의 VAE post들이 잘 설명해주니 확인해주세요.

VAE loss term 수식 VAE loss는 latent를 $z$로 표현하는데, 위 그림에서의 $x_T$를 $z$로 치환하면 좀 더 익숙하신 형태로 보이실 것입니다.
위 그림에서 확인할 수 있듯, VAE에서 수식을 전개해나갈때 사용하는 트릭은
- $\frac{q(x_T|x_0)}{q(x_T|x_0)}$를 곱해줌으로써 intractable KL divergence를 없애고, ELBO를 남기기
- ELBO 수식에서 bayesian 표현으로 갈라져나온 $p_\theta(x_T)$ (위 그림의 파란박스)가 latent의 KL divergence
- ELBO 수식에서 latent KL divergence를 제외한 나머지가 reconstruction term으로 남아 두 loss term으로 표현 가능으로 정리됩니다.
─ VAE의 수식전개에서 조금 비틀어서, DDPM의 loss 수식 전개는 아래에 ▼ ─
2-2) DDPM loss term

ELBO 식의 분모가 latent의 KL divergence loss가 되도록 가르는 것이 아니라 VAE에서 reconstruction term이 되는 분자와 합쳐집니다.
결국 맨 아래 수식을 살펴보게 되면 $p_\theta(x_0|x_T)$와 $q(x_T|x_0)$의 KL divergence를 최소화시키는 term이 됩니다.
1의 마지막에서 해소하고 싶었던 " $q$로부터 어떻게 $p$로 하여금 denoising process를 학습시킬 수 있을까요? " 의 질문이 수식적으로 등장했습니다. 두 분포의 condition과 target variable이 서로 반대입니다. 이를 수식으로 풀어내는 과정이 아래에서 나옵니다.
2-3) "seems intractable" to tractable
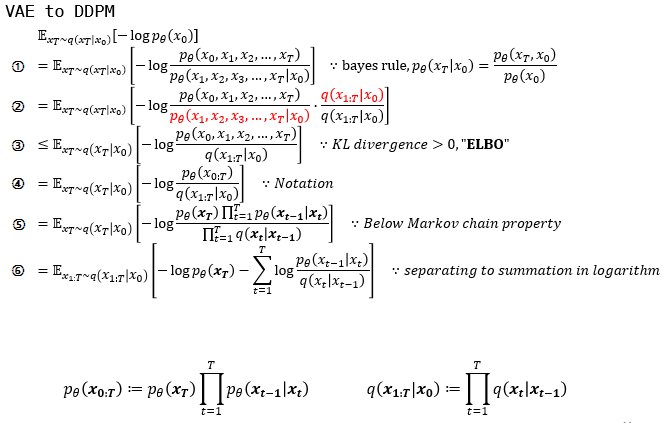
①: bayes rule을 바탕으로 multi-variable에 대한 conditional, joint probability로 나누었습니다.
②: VAE마냥 $\frac{q(x_T|x_0)}{q(x_T|x_0)}$를 곱해줍니다.
③: ②에서 빨간색으로 표현된 부분을 intractable한 KL divergence term으로 제거하고 ELBO를 남깁니다.
④: ③과 같은 식을 표현만 달리하였습니다.
⑤: $p$와 $q$가 markov chain임을 이용하여 Markov chain의 성질을 이용하였습니다.
⑥: log의 성질로 곱으로 표현된 부분을 합으로 나타내었습니다.
─ ▼아래에 계속 ─


⑦: [⑥의 수식과 같음]
⑧: sigma의 아래첨자의 $t$가 2가 되고 sigma 첫 번째 term을 뒤로 따로 빼냈습니다.
⑨: Markov chain의 성질로 나타낼 수 있는 부분입니다. 사실상 loss term을 만들어낼 때 제일 핵심이 되는 구간이라고 생각합니다. (VAE에서의 $\frac{q}{q}$ 곱하는 것에 버금가는 수식 전개 발상) 이 과정을 통해서 수식 내의 $p$와 $q$ distribution이 같은 condition으로부터 같은 target distribution을 나타내게 되었습니다.
⑩: log의 성질로 곱으로 표현된 부분을 합으로 나타내었습니다.
⑪: ⑩에서 log로 갈라져나온 term을 보면 $t=i$에서의 분모가 $t=i+1$에서의 분자와 약분(log 바깥에서 봤을땐 + - 상쇄)됩니다.
(고딩때 수열 연습문제 중에 sigma에서 같은 term인데 부호만 달라서 막 상쇄되고 첫 index +랑 마지막 index - 만 남는 문제 푸는 방식 그 발상입니다.)⑫: ⑪에 파란색 분모부분을 앞으로 빼고 남은 term을 정리해서 남겨놓습니다.
loss 수식 정리가 완성되었습니다. 총 3개의 term이 나왔는데, 각각이 어떤 의미를 가질까요?
2-4) Loss term 설명

①: $p$가 만드는 noise $x_T$의 분포와 data $x_0$로부터 $q$과정을 거쳐 만들어진 noise $x_T$의 분포간 KL divergence를 최소화합니다.
이 loss는 process를 매우 많이 진행하여 분모의 분포가 $x_T$가 $x_0$과 independent한 Gaussian distribution라고 가정하여 $p$ 또한 그냥 Gaussian distribution에서 sampling하는 방식을 취하여 이 term에 의해서는 neural net은 학습되지 않습니다.
②: latent상에서 $x_t$로부터 $x_{t-1}$의 분포를 예측하는 reverse process는 $q$가 Gaussian process일 경우 아래의 수식으로 나타낼 수 있습니다.
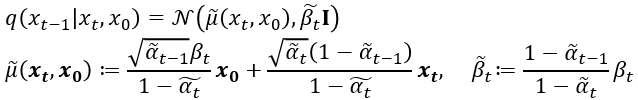
$q$의 Gaussian process 수식에서 위 그림의 아래 term을 도출할 수 있다고 논문에 나와있습니다.
만, 저는 성공하지 못했습니다....③: VAE의 reconstruction loss와 같은 역할을 합니다. latent $x_1$로부터 data인 $x_0$을 추정하는 확률 모델의 parameter를 최적화시킵니다.
3. ■■■...
학습 방법에서 사용되는 몇 가지 trick과 결과에 대해서는 다음 post에서 계속하겠습니다.
'Deep-learning' 카테고리의 다른 글
[논문 설명] Learnable Fourier Features for multi-dimensional spatial positional encoding 2 (0) 2022.09.05 [논문 요약]OEPG와 PAC Net - ICML 2022 accepted papers (0) 2022.07.12 [논문공부] (자세한 리뷰) Masked Autoencoders are Scalable Vision Learners (4) 2021.12.27 [논문공부] Denoising Diffusion Probabilistic Models (DDPM) 설명 2 (7) 2021.07.10 [논문과 코드] Attention is all you need *line-by-line (2) 2020.07.01